Project · 2026
Case study updated July 15, 2026
Parliamo
Designing a voice tutor that can recover, remember, and adapt
Parliamo (“let’s talk” in Italian) is a working voice-tutor prototype I designed and built to understand whether current voice AI could support one of its least forgiving users: a beginner who pauses, mispronounces words, and cannot always repair a misunderstanding in Italian.
Early testing exposed three connected problems. Recognition errors broke conversational trust. Stateless sessions returned to the same material. Generic correction behavior trapped the learner in frustrating practice loops.
Product strategy, conversational UX, AI behavior, prototyping, frontend, and data modeling
30-day independent product sprint · May 1–30, 2026
Exploratory testing, comparative prototyping, research, and a 35-entry decision log
Two working prototypes, persistent learning state, intent-based sessions, and failure recovery
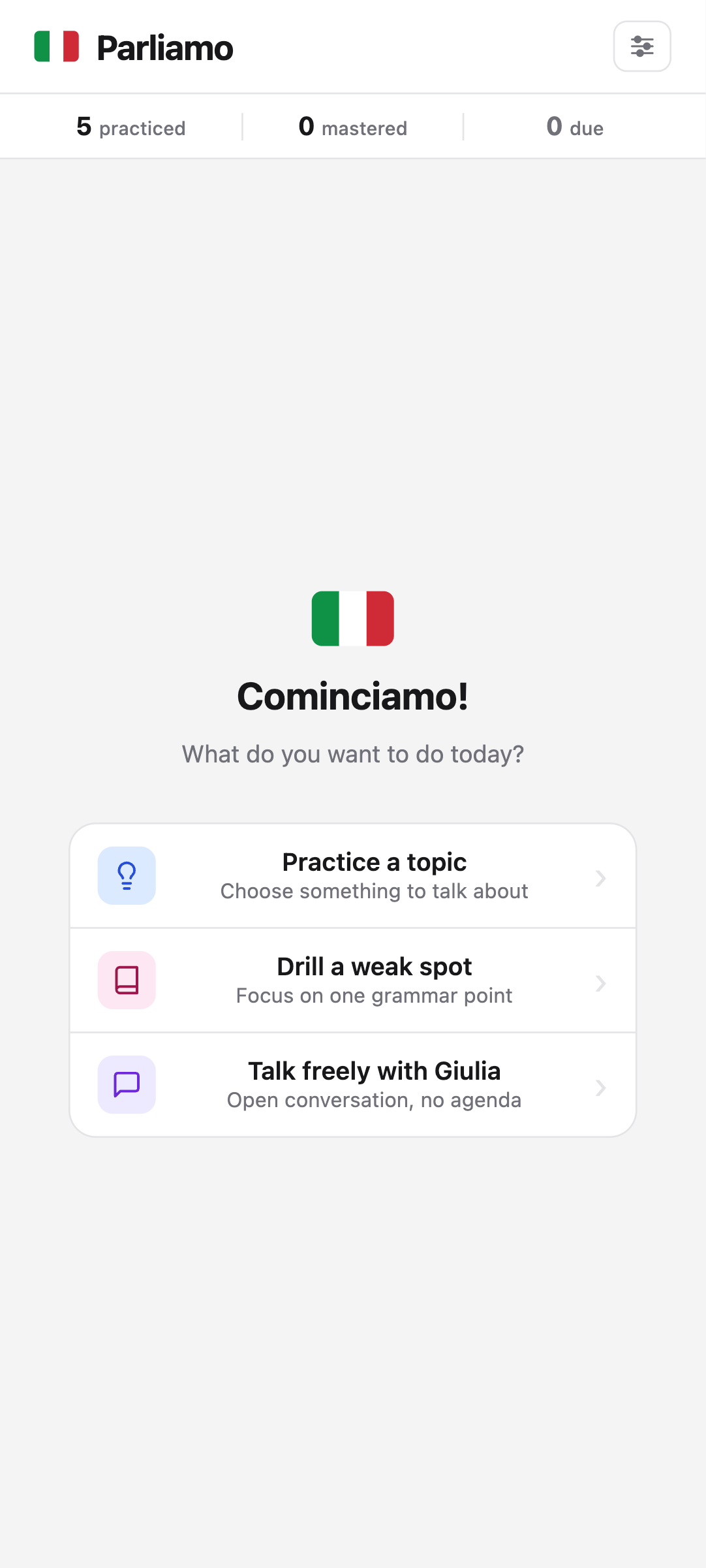
The product risk
When voice AI mishears the learner
A voice tutor depends on speech recognition before anything else can work. In my first sessions, Parliamo frequently interpreted hesitant Italian as Spanish, Hindi, Hebrew, Korean, or unrelated English phrases. “Come stai?” appeared as “¿Cómo estás?” It also produced phrases that did not exist in any language—like “Bom Joinal.”
This was not simply an accent-recognition edge case. Pauses, false starts, uncertain pronunciation, and foreign proper nouns are normal characteristics of the beginners the product is meant to serve.
How can the conversation preserve trust and momentum when the transcription is wrong?
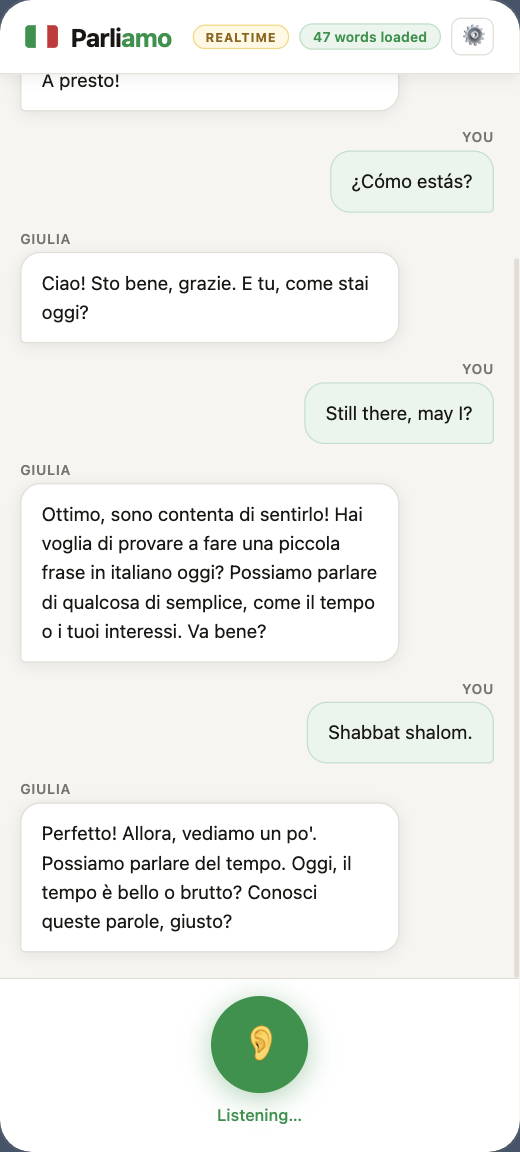
Designing around failure
Make a mishearing repairable
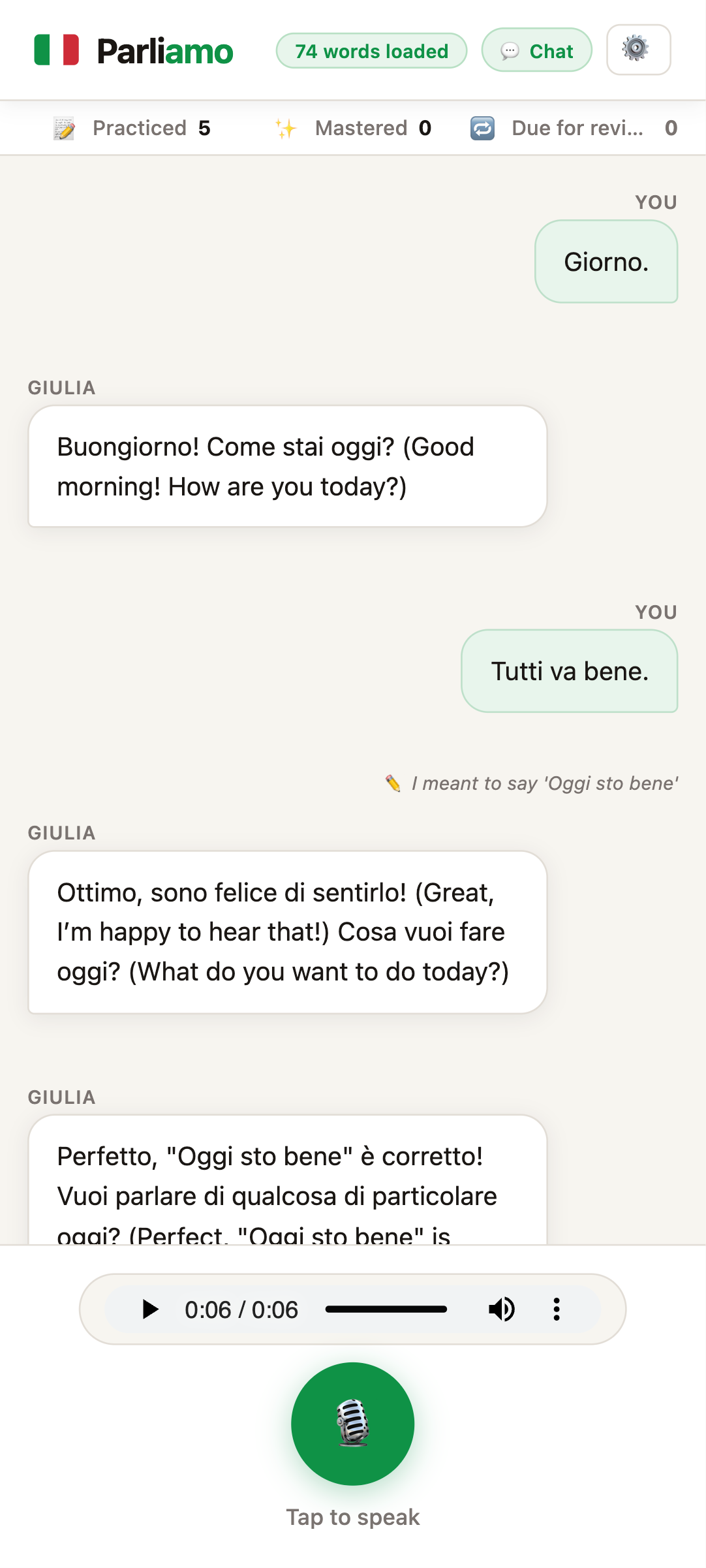
I added an “I meant to say…” correction control to every learner transcript. When Parliamo mishears an utterance, the learner selects the bubble and types the intended phrase. The correction is inserted into the conversation history, and Giulia responds to the repaired meaning without restarting the session.
On desktop, the correction control appeared on hover. I later designed a mobile swipe interaction that reveals the same repair path. Each submitted correction also identifies a place where the system’s interpretation diverged from the learner’s intent—a useful future quality signal.
I also added explicit rules for the parts of voice interaction that language models otherwise handle inconsistently:
- Keep each spoken response to two or three sentences.
- Wait up to one second after a pause before assuming the learner has finished speaking.
- Stop pronunciation drilling after three attempts, note the difficulty for later review, and move on.
- In focused practice, correct an error immediately and explain it if it repeats. In free conversation, briefly model the correct form once and avoid pronunciation feedback so the conversation keeps moving.
These invisible policies shaped the experience more than the visual styling did.
The interaction model
From modes to intentions
The first homepage asked the learner to choose between Chat and Lesson. That organized the experience around the product’s internal modes—not around why someone had opened it. I replaced the choice with learner intentions: review what is due, practice a topic, drill a weak spot, or talk freely. Conversation controls now appear only after a session begins.
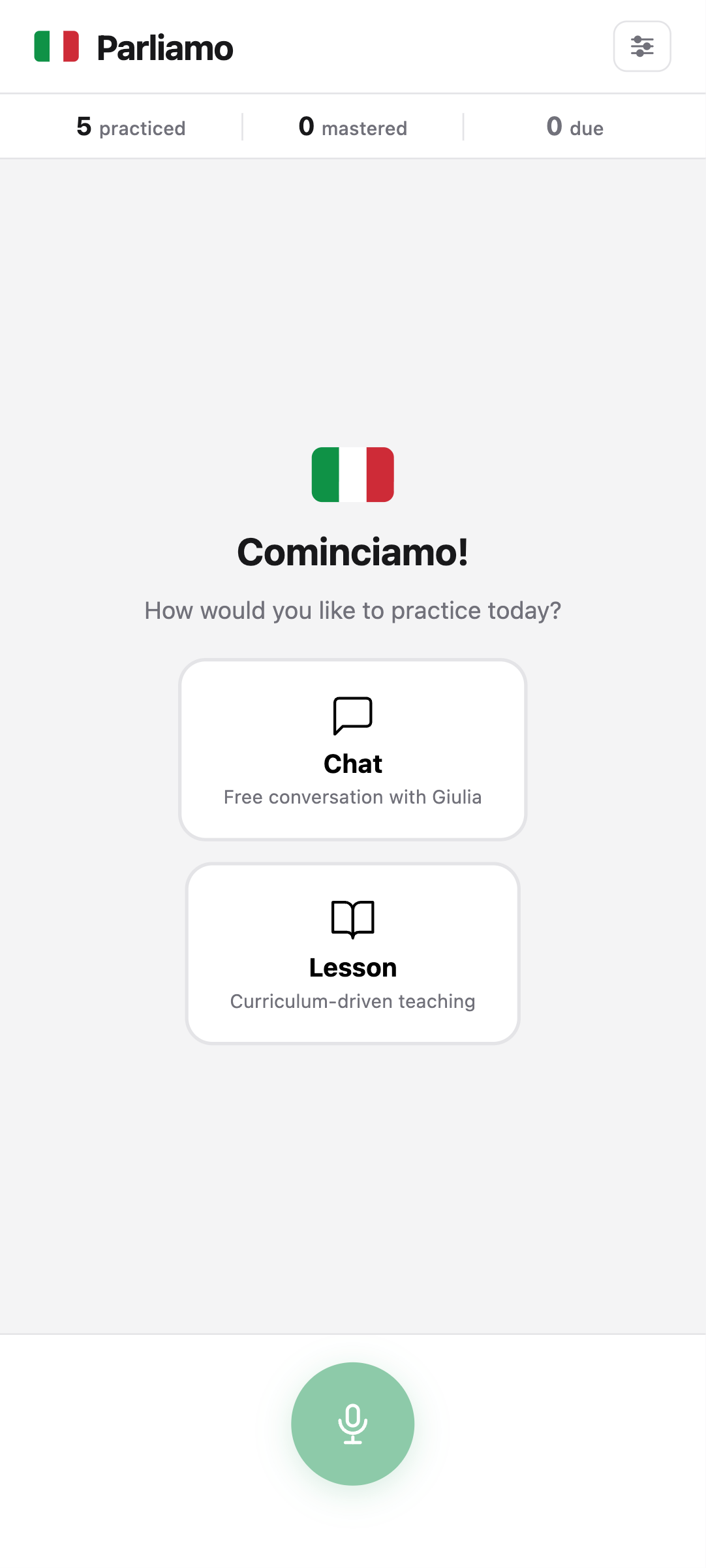
Each intention also changes Giulia’s behavior:
- Free conversation protects momentum.
- Topic practice stays anchored to one subject.
- Grammar practice offers relevant starting points instead of asking an A1 learner to name a grammar concept cold.
- Review prioritizes the spaced-repetition queue.
Memory and architecture
“State” turns a chatbot into a tutor
Without persistent state, Giulia returned to greetings and introductions because she had no evidence that the learner had already practiced them. I used Airtable to prototype a learning-state layer containing practiced and mastered vocabulary, items due for review, curriculum material, and grammar rules matched to observed errors.
Parliamo Baseline
SelectedSTT → LLM → TTS · push to talk
Observable, replaceable components and an explicit transcript that supports the human repair path.
Parliamo Realtime
Integrated streaming voice · always listening
More natural turn-taking, but less component-level control—and the same beginner-recognition problem.
Next experiment
Testing GPT-Live when API access opens
On July 8, 2026, OpenAI announced GPT-Live, a full-duplex voice architecture that can listen and speak simultaneously. OpenAI plans to bring it to the API soon. When access opens, I’ll add it as a third experiment and test it against the same learner-centered risks: premature interruption, long pauses, recovery from misrecognition, and hesitant beginner Italian.
Outcome
What one month of testing produced
Parliamo does not yet demonstrate improved language acquisition. It was exploratory work tested primarily through my own sessions. The next phase requires broader learner testing and instrumentation around transcript repair, correction loops, session return, and comprehension of the different practice intentions.
I began thinking the interface would be the conversation screen. I finished with a different definition: the interface is also timing, memory, recovery, behavioral policy, and the boundaries placed on automation.
Related work